Tutorial on Reinforcement Learning for Controller Design
Introduction

In this tutorial, you will learn how to use OpenAI gym to create a controller for the classic pole balancing problem. The problem will be solved using Reinforcement Learning. While this topic requires much involved discussion, here we present a simple formulation of the problem that can be efficiently solved using gradient descent. Also note that pole balancing can (should?) be solved by classic control theory, e.g., through a PID controller. However, the solution presented here does not require knowledge about the system (dynamics) other than the outcome of it (how long the pole is balanced).
Get Ready
Downloading this repo
To download the code, you can either click on the green button (Clone or download) to download as a zip, or use git.
Install prerequisites
-
You will first need to install Python 3.5. Check if python is correctly installed by type in the command line
python. You can find and open the command line by type incmdin the Windows search bar. NOTE: When installing Python, please choose to install pip, and include python in your environment path. -
Install TensorFlow (CPU version for Windows) here, or if you are on other OS, here.
-
Once done, go to the folder where you hold this example code, type in the windows command line (NOT under the python console):
pip install -r requirement.txt. This should install all dependancies. -
You can then run the code by typing in:
python main.py. Alternatively, you can install Pycharm and run/edit everything from there.
The design problem
Problem statement
The simple pole balancing (inverse pendulum) setting consists of a pole and a cart. The system states are the cart displacement \(x\), cart velocity \(\dot{x}\), pole angle \(\theta\), and pole angular velocity \(\dot{\theta}\). The parameters of the default system is as follows:
| Left-aligned | Center-aligned |
|---|---|
| mass cart | 1.0 |
| mass pole | 0.1 |
| pole length | 0.5 |
| force | 10.0 |
| delta_t | 0.02 |
| theta_threshold | 12 (degrees) |
| delta_t | 2.4 |
The controller takes in the system states, and outputs a fixed force on the cart to either left or right. The controller needs to be designed so that within 4 seconds, the pole angle does not exceed 12 degrees, and the cart displacement does not exceed 2.4 unit length. A trial will be terminated if the system is balanced for more than 4 seconds, or any of the constraints are violated.
The optimization problem
Here we learn a controller in a model-free fashion, i.e., the controller is learned without understanding of the dynamical system. We first introduce the concept of a Markov Decision Process: An MDP contains a state space, an action space, a transition function, a reward function, and a decay parameter \(\gamma\). In our case, the state space contains all possible combinations of \(x\), \(\dot{x}\), \(\theta\), \(\dot{\theta}\). The action space contains the force to the left, and the force to the right. The transition function \(s_{k+1} = T(s_k,a_k)\) computes the next state \(s_{k+1}\) based on the current state \(s_k\) and the action \(a_k\). In our case, the transition is given by the system equations. The reward function defines an instantaneous reward \(r_k = r(s_k)\). In our case, we define reward as 1 when the system does not fail, or 0 otherwise. The decay parameter \(\gamma\) defines a long term value of the controller \(\pi\): \(V_k(\pi,s_k) = r_k + \gamma V_{k+1}(\pi,T(s_k,a_k))\). \(\gamma\) describes how important future rewards are to the current control decision: larger decay (small \(\gamma\)) leads to more greedy decisions.
The goal of optimal control is thus to find a controller \(\pi\) that maximizes the expectation \(\mathbb{E}_{s_0,a_k}[V_0(\pi,s_0)]\). Specifically, we define the controller as a function of the states that outputs a number between 0 and 1: \(\pi(s,w)\). This number is treated as a probability for choosing action 0 (say, force to the left), and thus the probability for the other action is \(1-\pi(s,w)\). Thus \(V_0(\pi,s_0)\) is a random variable parameterized by \(w\).
The learning algorithm
A simple way to train a controller for binary outputs is as follows. Given a trial run with \(K\) time steps based on the current controller, we collect the instantaneous rewards \(r_k\), actions \(a_k\), and the controller outputs \(\pi_k\) for \(k=1,...,K\). We can minimize the following loss function
\(f(w) = -\sum_{k=1}^K (\sum_{j=k}^K \gamma^{j-k}r_j) (a_k\log(\pi_k)+(1-a_k)\log(1-\pi_k))\).
In this loss function, the first term \(\sum_{j=k}^K \gamma^{j-k}r_j\) represents the value at time step \(k\), the second term \(a_k\log(\pi_k)+(1-a_k)\log(1-\pi_k)\) is close to \(0\) when the favored action is chosen, and \(-\inf\) when the unfavored action is chosen. Essentially, this loss is minimized when all chosen control decisions \(a_k\) lead to high value. Thus by tuning \(w\), we correct the mistakes we made in the trial (i.e., high value from unfavored move, or low value from favored move).
In the code, you may notice that the values are normalized. According to this paper, this speeds up the training process.
Controller model
The controller is modeled as a single-layer neural network:
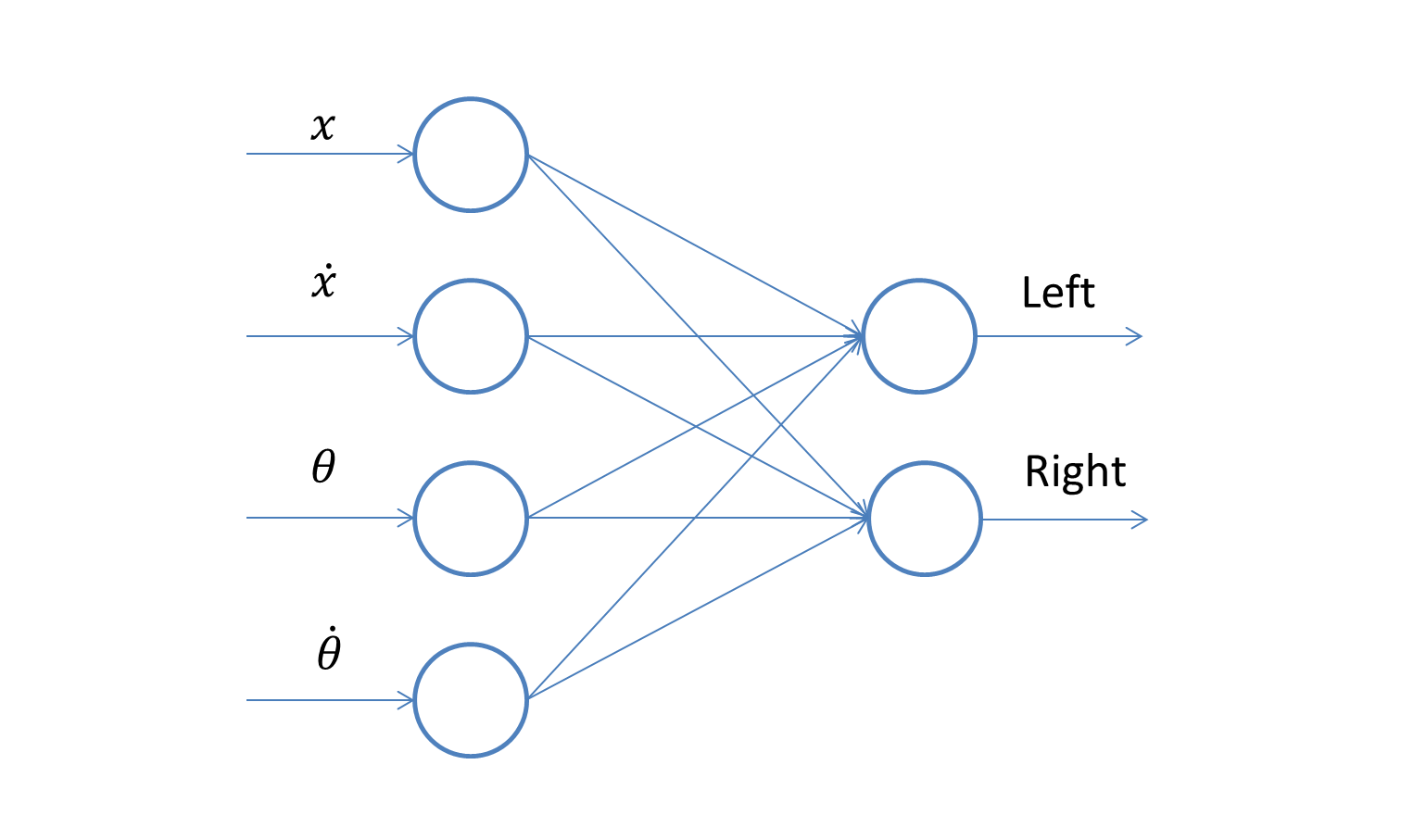
It is found that a single layer is already sufficient for this environment setting. If needed, you can replace the network with more complicated ones.
Training algorithm
Due to the probabilistic nature of the value function, we minimize an averaged loss \(F(w) = \sum_{t=1}^T f_t(w)\) over \(T\) trials. This is done by simply running the simulation \(T\) times, recording all data, and calculate the gradient of \(F(w)\). Notice that the gradient in this case will be stochastic, in the sense that we only use \(T\) random samples to approximate it, rather than finding the theoretical mean of \(\nabla_w F(w)\) (which does not have an analytical form anyway). The implementation of the gradient descent is [ADAM][adam], which we will discuss later in the class.
Results
With default problem settings, we can get a convergence curve similar this:
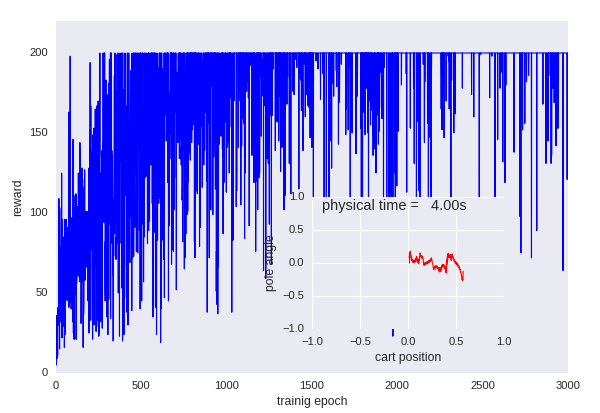
Y axis of the main plot is the total reward a policy achieves, X axis is the number of training epochs. The small window shows the normalized trajectory of cart positions and pole angles in the most recent trial. It can be seen that the learning achieves a good controller in the end.
To store videos, you will need to uncomment the line:
# self.env = wrappers.Monitor(self.env, dir, force=True, video_callable=self.video_callable)
By doing this, a serial of the simulation videos will be saved in the folder /tmp/trial.
Generalization of the problem
You can change problem parameters in gym_installation_dir/envs/classic_control/cartpole.py.
More details about the setup of this physical environment can be found
in the gym documents.
Details on how to derive the governing equations for single pole can be
found at this technical report.
Corresponding equations for how to generalize this to multiple poles
can also be found at this paper