Improving Design Preference Prediction Accuracy using Feature Learning
Collaborators: Burnap, A., Pan, Y., Liu, Y., Ren, Y., Lee, H., Gonzalez, R. and Papalambros, P.Y.Abstract
Quantitative preference models are used to predict customer choices among design alternatives by collecting prior purchase data or survey answers. This paper examines how to improve the prediction accuracy of such models without collecting more data or changing the model. We propose to use features as an intermediary between the original customer linked design variables and the preference model, transforming the original variables into a feature representation that captures the underlying design preference task more effectively. We apply this idea to automobile purchase decisions using three feature learning methods (principal component analysis, low rank and sparse matrix decomposition, and exponential sparse restricted Boltzmann machine), and show that the use of features offers improvement in prediction accuracy using over 1 million real passenger vehicle purchase data. We then show that the interpretation and visualization of these feature representations may be used to help augment data-driven design decisions.
Images
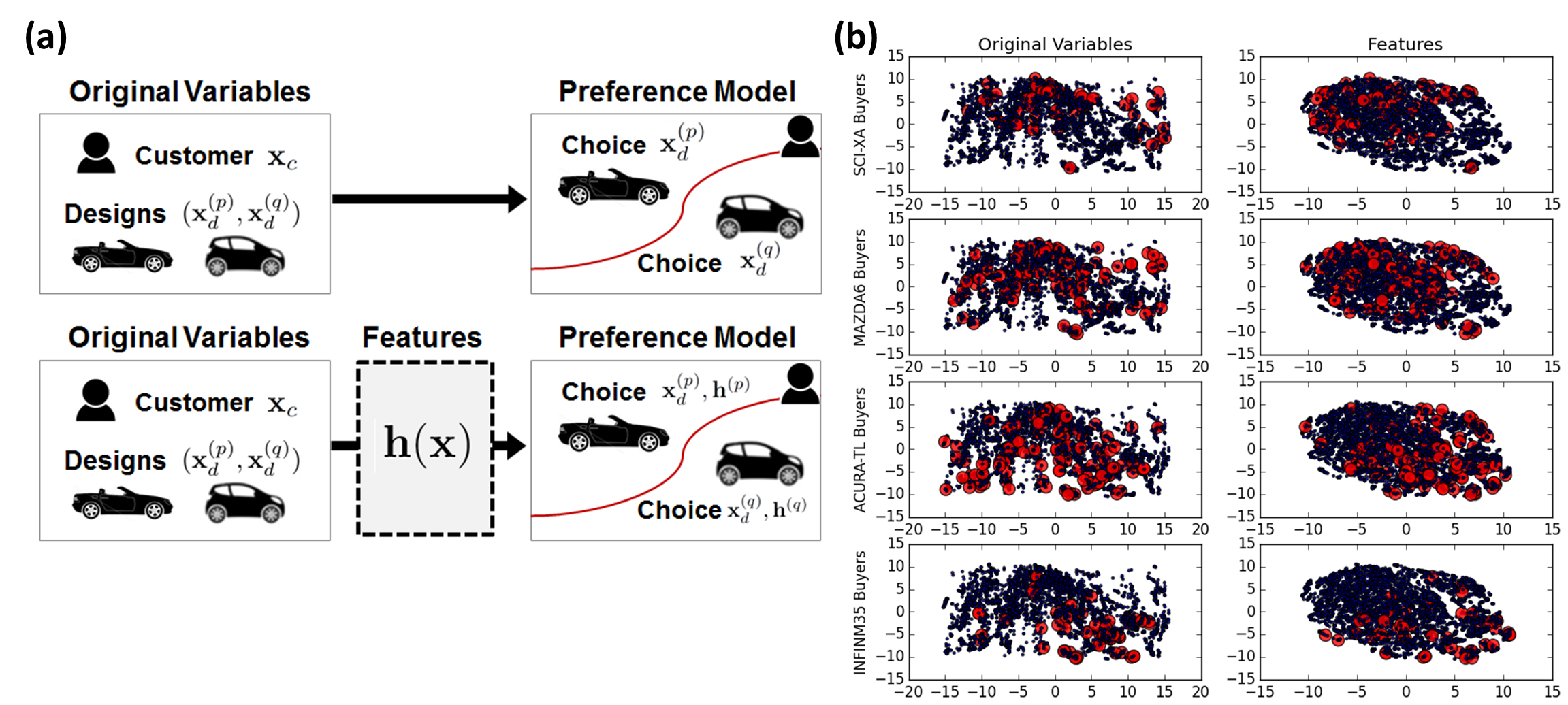
(a) The concept of feature learning as an intermediate mapping between variables and a preference model (b) Optimal vehicle distribution visualization. Every point represents the optimal vehicle for one consumer. In the left column, the optimal vehicle is inferred using the utility model with original variables. In the right column, LSD features are used to infer the optimal vehicle. In the first row, the optimal vehicles from SCI-XA buyers are marked in big red points. Similarly, the optimal vehicles from MAZDA6, ACURA-TL and INFINM35 buyers are marked in big red points respectively.
Related Papers
1.